Yolov5 深度相机
演示视频
本项目基于
- yolov5:https://github.com/ultralytics/yolov5
- yolov5-D435i:https://github.com/killnice/yolov5-D435i
前言
yolov5是一种非常优秀的视觉库,使用yolov5我们可以很轻松的得到检测物体在画面中的二维位置,但在很多场景下,我们希望能够得到物体与我们的距离(深度)。深度的获取主要有两种主流方式,一种为双目,利用画面视察计算距离,与人眼比较像;一种既使用带有深度摄像头的相机,直接获得距离信息。
本文既将介绍使用深度相机的方式,配合yolov5获取物体的位置和距离。
深度相机有很多种,但种的来说,本文的中心思路就是使用yolov5配合color画面,得到物体边缘坐标;再将区域内的位置转换到depth画面中,在相应的区域截取每个像素的深度值,进行排序,滤波,得出较为稳定的值,输出为距离。
深度相机驱动
我们需要通过相机获得一个color图像和一个depth图像,在这里我使用了微软的kinect相机
详情参阅:Linux下各种相机的驱动安装 & Ylt's Wiki (yltzdhbc.top)
在保证能够驱动相机之后,再进行下一步
安装Yolov5
yolov5安装与环境配置参阅:初识Yolov5-安装与环境配置 & Ylt's Wiki (yltzdhbc.top)
同样,保证环境安装正确之后,进行下一步
Demo
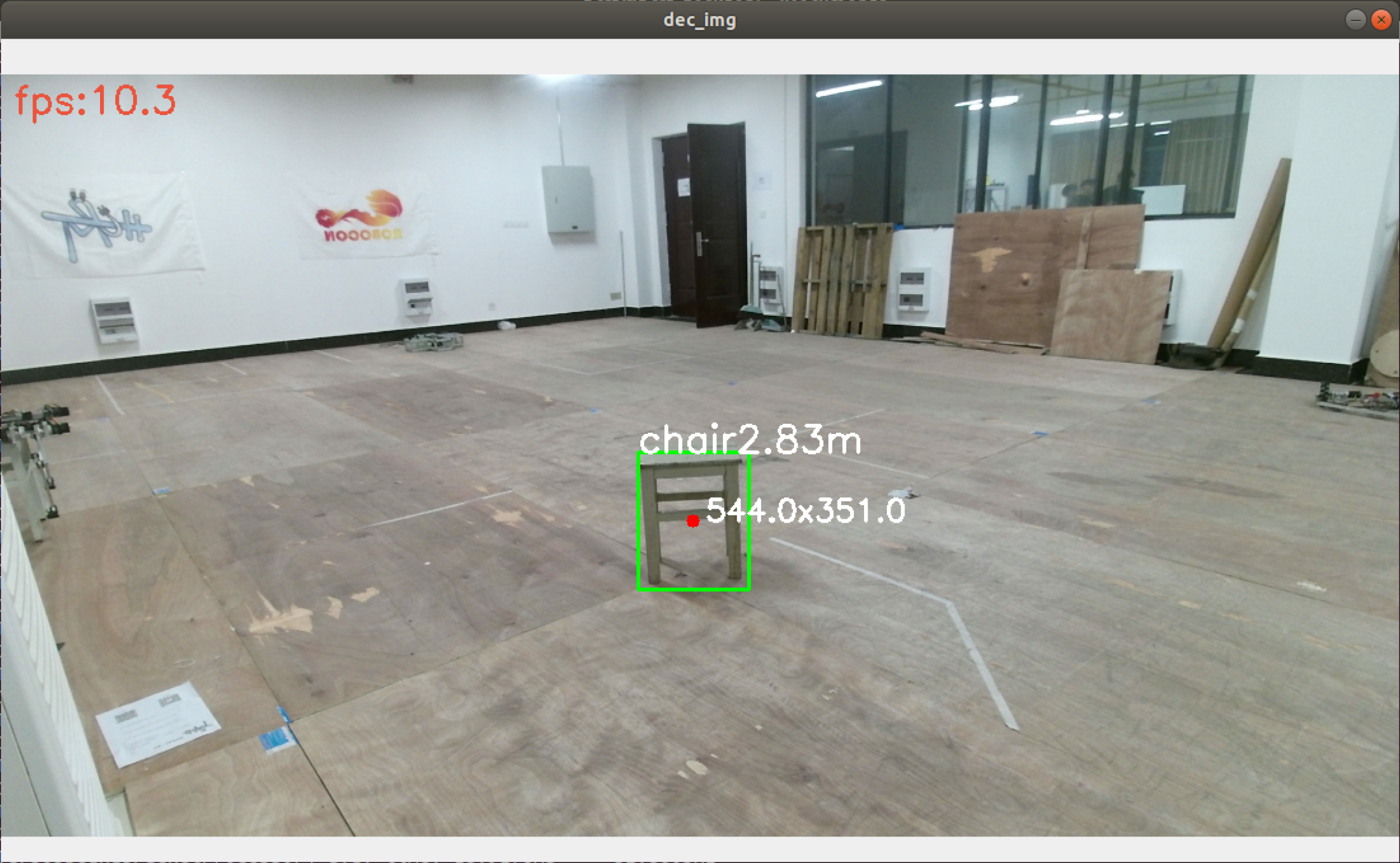
本demo实现了基本物体识别与深度计算(ubunt18.04+kinect),并使用opencv绘制出框图,深度,位置,FPS等信息
前置条件为 cv2、numpy、cython库,如没有则使用以下命令安装
pip3 install opencv-python
pip3 install numpy
pip3 install cython
将以下放到本地保存为.py文件运行即可,注意第一次运行程序程序会从云端下载yolov5的pt文件
# coding: utf-8
import numpy as np
import cv2
import sys
import torch
import random
from pylibfreenect2 import Freenect2, SyncMultiFrameListener
from pylibfreenect2 import FrameType, Registration, Frame
import time
# model = torch.hub.load('ultralytics/yolov5', 'yolov5l6')
# model = torch.hub.load('ultralytics/yolov5', 'yolov5x6')
# model = torch.hub.load('ultralytics/yolov5', 'yolov5s6')
model = torch.hub.load('ultralytics/yolov5', 'yolov5n6')
model.conf = 0.5
def get_mid_pos(frame, box, depth_data, randnum):
distance_list = []
mid_pos = [(box[0] + box[2])//2, (box[1] + box[3])//2] # 确定索引深度的中心像素位置
min_val = min(abs(box[2] - box[0]), abs(box[3] - box[1])) # 确定深度搜索范围
# print(box)
for i in range(randnum):
bias = random.randint(-min_val//4, min_val//4)
dist = depth_data[int(mid_pos[1] + bias), int(mid_pos[0] + bias)]
cv2.circle(
frame, (int(mid_pos[0] + bias), int(mid_pos[1] + bias)), 4, (255, 0, 0), -1)
#print(int(mid_pos[1] + bias), int(mid_pos[0] + bias))
if dist:
distance_list.append(dist)
distance_list = np.array(distance_list)
distance_list = np.sort(distance_list)[
randnum//2-randnum//4:randnum//2+randnum//4] # 冒泡排序+中值滤波
#print(distance_list, np.mean(distance_list))
return np.mean(distance_list), mid_pos
def dectshow(org_img, boxs, depth_data, fps):
img = org_img.copy()
for box in boxs:
cv2.rectangle(img, (int(box[0]), int(box[1])),
(int(box[2]), int(box[3])), (0, 255, 0), 2)
dist, mid_pos = get_mid_pos(org_img, box, depth_data, 24)
cv2.circle(img, (int(mid_pos[0]), int(mid_pos[1])), 5, (0, 0, 255), -1)
cv2.putText(img, box[-1] + str(dist / 1000)[:4] + 'm',
(int(box[0]), int(box[1])), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2)
cv2.putText(img, str(mid_pos[0]) + 'x' + str(mid_pos[1]),
(int(mid_pos[0]) + 10, int(mid_pos[1])), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (255, 255, 255), 2)
cv2.putText(img, 'fps:' + str(round(fps, 1)),
(10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (61, 84, 234), 2)
cv2.imshow('dec_img', img)
if __name__ == "__main__":
try:
from pylibfreenect2 import OpenGLPacketPipeline
pipeline = OpenGLPacketPipeline()
except:
try:
from pylibfreenect2 import OpenCLPacketPipeline
pipeline = OpenCLPacketPipeline()
except:
from pylibfreenect2 import CpuPacketPipeline
pipeline = CpuPacketPipeline()
print("Packet pipeline:", type(pipeline).__name__)
fn = Freenect2()
num_devices = fn.enumerateDevices()
if num_devices == 0:
print("No device connected!")
sys.exit(1)
serial = fn.getDeviceSerialNumber(0)
device = fn.openDevice(serial, pipeline=pipeline)
listener = SyncMultiFrameListener(
FrameType.Color | FrameType.Ir | FrameType.Depth)
# Register listeners
device.setColorFrameListener(listener)
device.setIrAndDepthFrameListener(listener)
device.start()
# NOTE: must be called after device.start()
registration = Registration(
device.getIrCameraParams(), device.getColorCameraParams())
undistorted = Frame(512, 424, 4)
registered = Frame(512, 424, 4)
try:
while True:
start = time.time()
# Wait for a coherent pair of frames: depth and color
frames = listener.waitForNewFrame()
color_frame = frames["color"]
depth_frame = frames["depth"]
registration.apply(color_frame, depth_frame, undistorted, registered,
bigdepth=None, color_depth_map=None)
if not depth_frame or not color_frame:
continue
# Convert images to numpy arrays
depth_image = cv2.resize(
depth_frame.asarray(), (int(1100 / 1), int(600 / 1)))
color_image = cv2.resize(
color_frame.asarray(), (int(1100 / 1), int(600 / 1)))
results = model(color_image)
boxs = results.pandas().xyxy[0].values
end = time.time()
seconds = end - start
fps = 1 / seconds
dectshow(color_image, boxs, depth_image, fps)
key = cv2.waitKey(1)
listener.release(frames)
# Press esc or 'q' to close the image window
if key & 0xFF == ord('q') or key == 27:
cv2.destroyAllWindows()
break
finally:
# Stop streaming
device.stop()
device.close()
运行效果: